JavaGuide 学习笔记
JIT(Just in Time Compilation)和 AOT(Ahead of Time Compilation)
| 对比维度 | JIT(即时编译) | AOT(提前编译) |
|---|---|---|
| 编译时机 | 运行时编译 | 运行前编译 |
| 启动速度 | 较慢(需要预热) | 快(无需预热) |
| 峰值性能 | 更高(运行时优化) | 较低(缺少运行时信息) |
| 内存占用 | 较高 | 较低 |
| 打包体积 | 较小 | 较大(包含机器码) |
| 动态特性支持 | 完全支持 | 受限(反射、动态代理等) |
| 适用场景 | 长时间运行的服务 | 云原生、Serverless、CLI工具 |
AOT主要优势在于启动时间,内存占用,JIT则具有更高的极限处理能力,可以降低请求的最大延迟。
AOT因为其提前编译的特性,无法使用比如Spring,ASM等技术。当需要支持类似的动态特性时,使用JIT及时编译器。
基本数据类型存放在栈中是一个常见的误区。 基本数据类型的存储位置取决于它们的作用域和声明方式。如果它们是局部变量,那么它们会存放在栈中;如果它们是成员变量,那么它们会存放在堆/方法区/元空间中。
为什么浮点数运算的时候会有精度丢失的风险?
计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。
BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
静态变量
静态变量也就是被 static 关键字修饰的变量。它可以被类的所有实例共享,无论一个类创建了多少个对象,它们都共享同一份静态变量。也就是说,静态变量只会被分配一次内存,即使创建多个对象,这样可以节省内存。
Object
/**
* native 方法,用于返回当前运行时对象的 Class 对象,使用了 final 关键字修饰,故不允许子类重写。
*/
public final native Class<?> getClass()
/**
* native 方法,用于返回对象的哈希码,主要使用在哈希表中,比如 JDK 中的HashMap。
*/
public native int hashCode()
/**
* 用于比较 2 个对象的内存地址是否相等,String 类对该方法进行了重写以用于比较字符串的值是否相等。
*/
public boolean equals(Object obj)
/**
* native 方法,用于创建并返回当前对象的一份拷贝。
*/
protected native Object clone() throws CloneNotSupportedException
/**
* 返回类的名字实例的哈希码的 16 进制的字符串。建议 Object 所有的子类都重写这个方法。
*/
public String toString()
/**
* native 方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
*/
public final native void notify()
/**
* native 方法,并且不能重写。跟 notify 一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
*/
public final native void notifyAll()
/**
* native方法,并且不能重写。暂停线程的执行。注意:sleep 方法没有释放锁,而 wait 方法释放了锁 ,timeout 是等待时间。
*/
public final native void wait(long timeout) throws InterruptedException
/**
* 多了 nanos 参数,这个参数表示额外时间(以纳秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 纳秒。。
*/
public final void wait(long timeout, int nanos) throws InterruptedException
/**
* 跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
*/
public final void wait() throws InterruptedException
/**
* 实例被垃圾回收器回收的时候触发的操作
*/
protected void finalize() throws Throwable { }
hashcode()
hashcode()用于获取hash码,这个码用于确定该对象在hash表中的索引位置。
当把对象加入HashSet中,会先调用hashcode()获取hash码,再进行一次简单的转换,决定这个对象应该存在底层的哪个桶(bucket)里。
如果是空桶则直接插入,反之则在这个桶中的链表或红黑树中逐个比较:
- 对于hash值不同的节点,直接跳过;
- 对应hash值相同的节点,进一步调用equals(),返回true代表集合中已有等价的元素,HashSet中不会再次加入,返回false则作为新节点存入该桶的链表或红黑树。
为什么重写 equals() 时必须重写 hashCode() 方法?
因为两个相等的对象的 hashCode 值必须是相等。也就是说如果 equals() 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals() 方法判断是相等的两个对象,hashCode 值却不相等。
String
StringBuffer 与 StringBuilder
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,而使用StringBuffer 与 StringBuilder时,会对对象本身进行操作,而不是生成新的对象并改变对象引用。
这两者都继承自AbstractStringBuilder类,StringBuffer对方法和调用的方法都加了同步锁,所以线程安全,StringBuilder没有对方法加同步锁,所以非线程安全。
两者的性能差异主要来源于线程安全机制:
- StringBuffer 的方法通常是同步的(线程安全),因此会带来一定的性能开销;
- StringBuilder 没有同步开销(非线程安全),在单线程场景下通常具有更好的性能表现。
字符串常量池
// 1.在字符串常量池中查询字符串对象 "ab",如果没有则创建"ab"并放入字符串常量池
// 2.将字符串对象 "ab" 的引用赋值给 aa
String aa = "ab";
// 直接返回字符串常量池中字符串对象 "ab",赋值给引用 bb
String bb = "ab";
System.out.println(aa==bb); // trueThrowable
Java中所有异常的父类,java.lang.Throwable ,有两个重要的子类:
- Exception: 程序本身可以处理的异常。又分为Checked Exception (必须处理)和 Unchecked Exception (非必须处理)
- Error: 程序本身无法处理的错误。比如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有:IO 相关的异常、ClassNotFoundException、SQLException 。
Unchecked Exception 即 不受检查异常 ,Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。RuntimeException 及其子类都统称为非受检查异常,常见的有:
- NullPointerException(空指针错误)
- IllegalArgumentException(参数错误比如方法入参类型错误)
- NumberFormatException(字符串转换为数字格式错误,IllegalArgumentException的子类)
- ArrayIndexOutOfBoundsException(数组越界错误)
- ClassCastException(类型转换错误)
- ArithmeticException(算术错误)
- SecurityException (安全错误比如权限不够)
- UnsupportedOperationException(不支持的操作错误比如重复创建同一用户)
try-with-resources
// 此处的资源必须实现java.lang.AutoCloseable 或者java.io.Closeable,多个资源中间用分号分割
try(Scanner scanner = new Scanner(new File("test.txt"))){
} catch(){
}
| 特性 | 传统 try-catch-finally | try-with-resources |
|---|---|---|
| 代码量 | 冗长 | 简洁 |
| 资源关闭 | 手动,易遗漏 | 自动,编译期保证 |
| 异常处理 | 关闭异常可能覆盖主异常 | 关闭异常被抑制,主异常保留 |
| 可读性 | 较差(关闭逻辑分散) | 高(资源管理集中) |
异常使用有哪些需要注意的地方?
- 不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
- 抛出的异常信息一定要有意义。
- 建议抛出更加具体的异常,比如字符串转换为数字格式错误的时候应该抛出NumberFormatException而不是其父类IllegalArgumentException。
- 避免重复记录日志:如果在捕获异常的地方已经记录了足够的信息(包括异常类型、错误信息和堆栈跟踪等),那么在业务代码中再次抛出这个异常时,就不应该再次记录相同的错误信息。重复记录日志会使得日志文件膨胀,并且可能会掩盖问题的实际原因,使得问题更难以追踪和解决。
集合
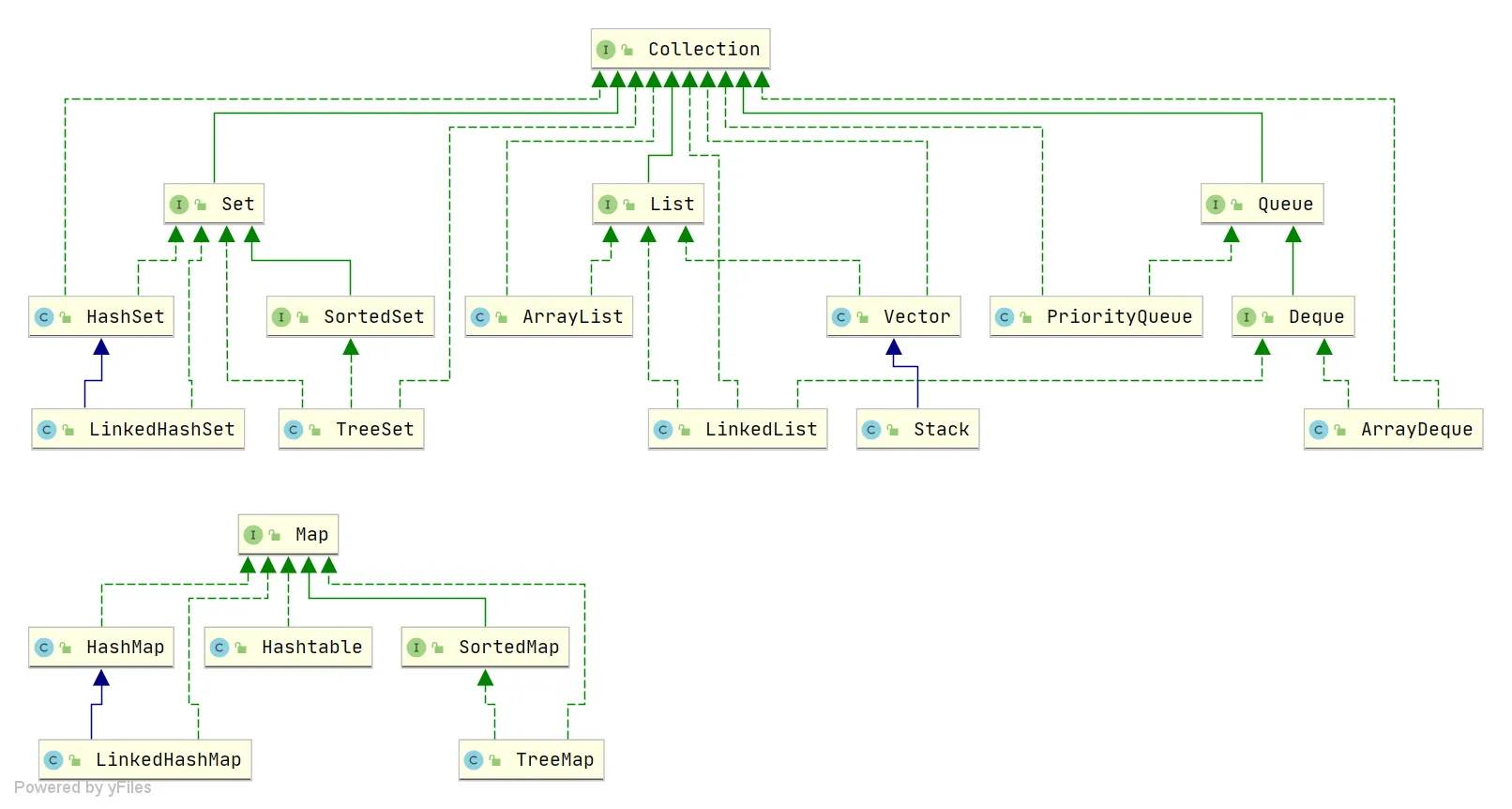
List Set Queue Map
- List 存储有序的可重复的元素。
- Set 存储不可重复的元素
- Queue 按特定的排队规则来确定先后顺序,存储有序的可重复的元素
- Map 使用键值对存储元素,key无序且不可重复,value无序可重复
List
- ArrayList:
Object[]数组 - Vector:
Object[]数组 - LinkedList: 双向链表
Set
- HashSet:基于HashMap实现,无序且唯一。
- LinkedHashSet:是HashSet 的子类,内部通过LinkedHashMap 实现
- TreeSet 红黑树,有序且唯一
Queue
- PriorityQueue:优先级队列
- DelayQueue :延迟队列
- ArrayDeque: 可扩容的动态双向数组
Map
- HashMap:由数组和链表组成,当链表长度大于阈值(默认8)时,将链表转化为红黑树
- LinkedHashMap:继承自HashMap,增加了一条双向链表,使可以保持键值对的插入顺序。
- HashTable:数组与链表组成的
- TreeMap:红黑树
List
ArrayList 和Array 的区别
- ArrayList 会动态的扩容与缩容,Array创建后就无法修改了
- ArrayList 允许使用泛型来确保类型安全,Array不可以
- ArratList 中只能存储对象,对于基本类型数据,需要使用包装类,Array可以直接储存基本数据类型
- ArrayList 支持插入,删除,遍历等常见操作,Array 只能通过下标访问元素
- ArrayList 创建时不需要制定大小,Array 需要
ArrayList 插入和删除元素的时间复杂度
对于插入:
- 头部插入:由于需要将所有元素都依次向后移动一个位置,因此时间复杂度是 O(n)。
- 尾部插入:当 ArrayList 的容量未达到极限时,往列表末尾插入元素的时间复杂度是 O(1),因为它只需要在数组末尾添加一个元素即可;
- 当容量已达到极限并且需要扩容时,则需要执行一次 O(n) 的操作将原数组复制到新的更大的数组中,然后再执行 O(1) 的操作添加元素。
- 指定位置插入:需要将目标位置之后的所有元素都向后移动一个位置,然后再把新元素放入指定位置。这个过程需要移动平均 n/2 个元素,因此时间复杂度为 O(n)。
对于删除:
- 头部删除:由于需要将所有元素依次向前移动一个位置,因此时间复杂度是 O(n)。
- 尾部删除:当删除的元素位于列表末尾时,时间复杂度为 O(1)。
- 指定位置删除:需要将目标元素之后的所有元素向前移动一个位置以填补被删除的空白位置,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
LinkedList 插入与删除元素的时间复杂度
- 头部/尾部进行插入/删除:只要修改头/尾的指针就可以完成操作,时间复杂度为 O(1)。
- 指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,不过由于有头尾指针,可以从较近的指针出发,因此需要遍历平均 n/4 个元素,时间复杂度为 O(n)。